Notes from Dex Horthy’s “No Vibes Allowed: Solving Hard Problems in Complex Codebases” talk at AI Engineer.
AI coding tools are getting better fast, but many engineering teams are running into the same disappointing pattern: agents look impressive on greenfield demos, then become unreliable when pointed at a mature production codebase.
That gap matters. Most real software work is not “build a shiny dashboard from scratch.” It is navigating a brownfield system with old decisions, implicit contracts, fragile tests, weird deployment constraints, and code paths nobody has touched in three years. In that environment, AI can increase throughput — but it can also create a tech debt factory if teams treat the agent like a magic senior engineer.
Dex Horthy’s talk makes a useful argument for developers: the bottleneck is not just model intelligence. It is context management. If the agent is stateless and only knows what is in the current conversation, then the quality of that conversation becomes part of your software engineering system.
In other words: better tokens in, better tokens out.
The naive coding-agent loop breaks down quickly
The simplest way to use a coding agent is also the most fragile:
- Ask it to implement something.
- Watch it misunderstand the codebase.
- Correct it.
- Watch it patch over the mistake.
- Correct it again.
- Repeat until the context window is polluted or everyone gives up.
This works for small edits. It is a bad workflow for complex tasks because every wrong turn becomes part of the agent’s context. The model is not “remembering” in the human sense; it is predicting the next useful action from the accumulated transcript. If that transcript contains false assumptions, failed attempts, noisy command output, and frustrated steering, you have made the next prediction harder.
Horthy calls out an important practical smell: if the agent starts apologizing and thrashing, it may be time to stop correcting and start over. A fresh context window with a better compressed brief is often more effective than continuing to steer a contaminated one.
Context windows have a “smart zone” and a “dumb zone”
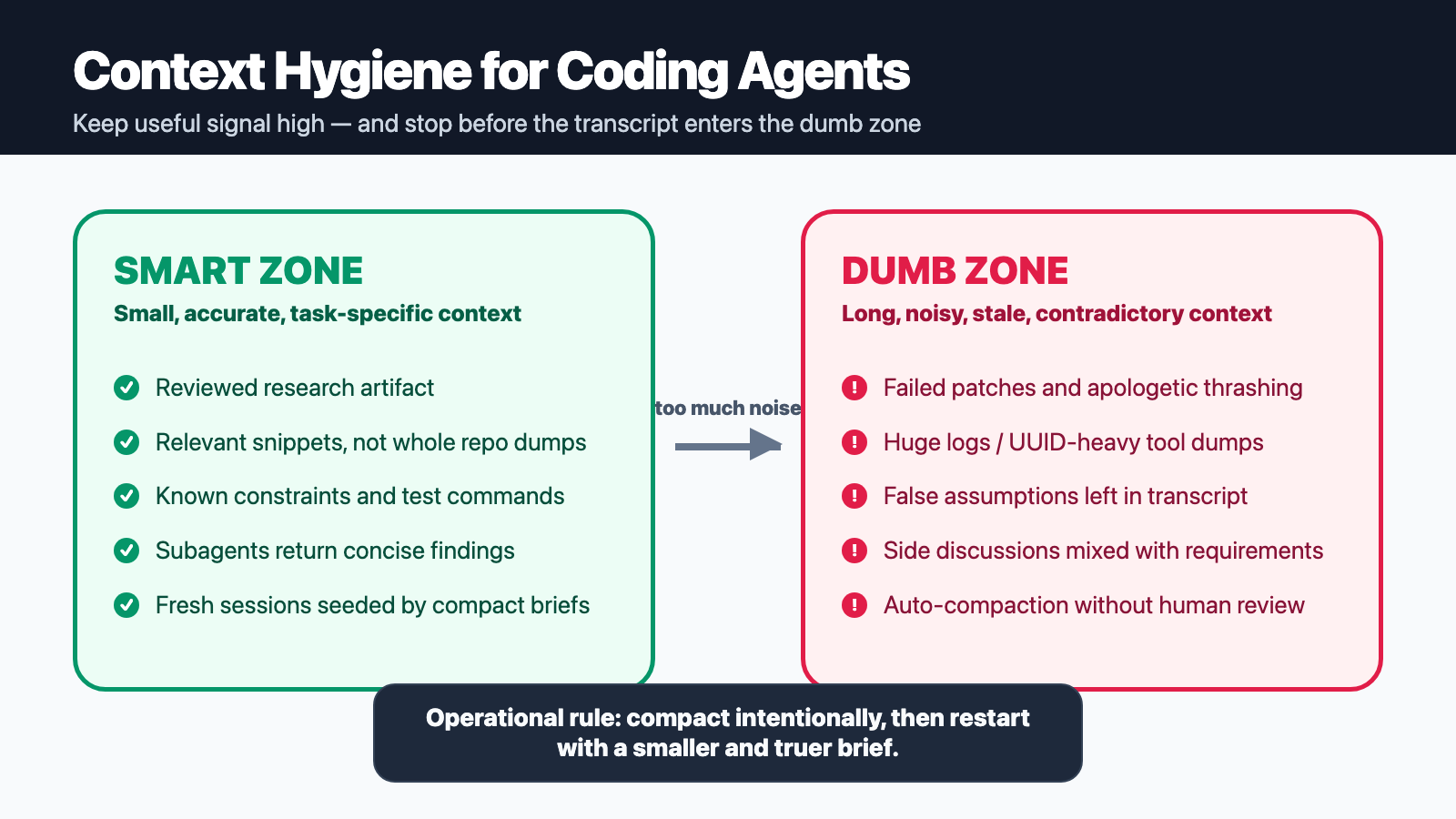
Context quality determines whether a coding agent stays in the productive smart zone or drifts into noisy, unreliable behavior.
A large context window sounds like a solution, but it is not free. Long contexts are harder for models to use reliably, and coding agents burn context quickly:
- File search results
- Whole-file reads
- Test output
- Build logs
- Failed patches
- Tool-call traces
- MCP responses full of JSON and UUIDs
- Human corrections and side discussions
The talk uses the idea of a “dumb zone”: the point where enough of the context window is filled with noise or stale information that the model’s decisions degrade. The exact percentage depends on model, task, and tool, but the operational lesson is durable: do not treat the context window like an infinite scratchpad.
For developers, this reframes agent performance. If the model is failing, the fix is not always “use a bigger model” or “write a more emotional prompt.” Sometimes the right move is to reduce context, remove bad assumptions, and feed the model a smaller, truer representation of the task.
Intentional compaction: turn messy work into a useful artifact
One of the most practical techniques in the talk is intentional compaction. Instead of letting the conversation grow until the tool auto-compacts or loses coherence, you deliberately summarize the useful state into a Markdown artifact.
A good compaction does not say, “We tried some things and edited auth.” It captures the details that matter for the next agent run:
- The specific problem being solved
- Relevant files and line numbers
- Known constraints
- Decisions already made
- Failed approaches to avoid
- Test commands and expected results
- Open questions that still require human judgment
That artifact can then seed a fresh session. The next agent does not need to rediscover the entire code path or re-run broad searches. It starts with a reviewed, compressed version of the truth.
This is especially important in brownfield work. When the codebase is large, the expensive step is often not editing code; it is finding the correct place to make the edit without breaking hidden assumptions.
Subagents are for context control, not roleplay
One of the sharper points from the talk: subagents are not mainly about pretending to have a frontend engineer, backend engineer, QA engineer, and data scientist sitting in a tiny org chart.
Subagents are useful because they isolate context.
For example, the parent agent can ask a subagent to investigate how billing retries work. The subagent can search widely, read long files, inspect tests, and burn its own context window. Then it returns a short answer:
The retry policy is defined in
payments/retry_policy.ts; the integration tests are inpayments/__tests__/retry_policy.test.ts; the queue worker calls it fromworkers/payment_retry_worker.ts.
Now the parent has the useful result without inheriting the entire messy investigation. This is the real leverage: separate exploration from execution.
Used well, subagents become a way to perform targeted research while keeping the main implementation context small and actionable.
Research → Plan → Implement is a workflow, not a magic acronym
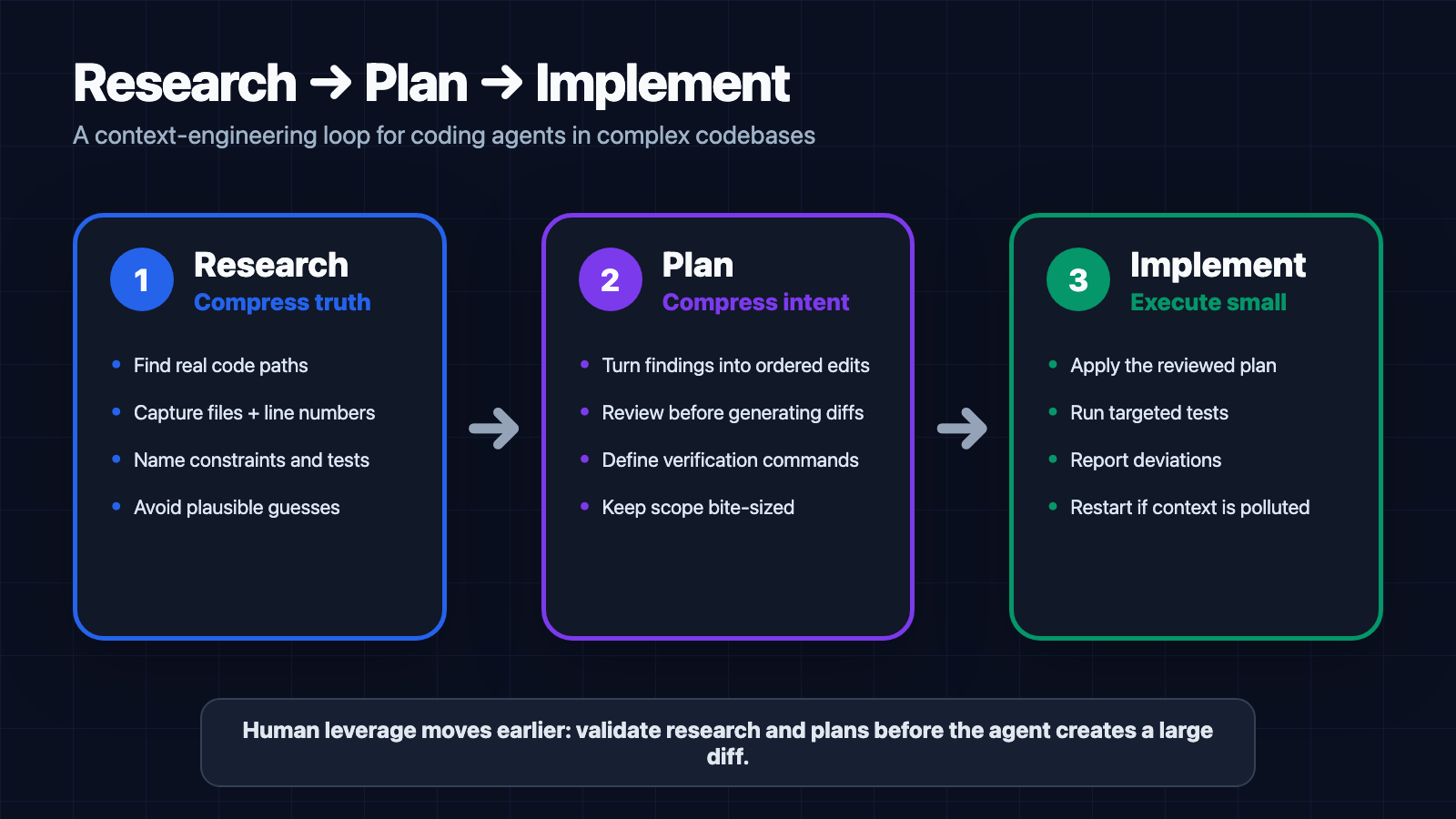
Separate exploration, planning, and execution so each phase starts from compact, reviewed context.
The talk’s core workflow is Research, Plan, Implement. The important part is not the acronym. The important part is repeated compaction at the boundaries between phases.
1. Research: compress truth
Research is about understanding how the system actually works. The goal is not to generate a plausible explanation. The goal is to produce a grounded snapshot of the relevant code paths, based on the source of truth: the code.
Good research answers questions like:
- Which files matter?
- What data flows through the system?
- Where are the existing tests?
- What conventions does this area follow?
- What constraints would a careless implementation violate?
This is where many coding-agent failures begin. If the research is wrong, the plan will be wrong. If the plan is wrong, the implementation can produce hundreds of lines of confidently incorrect code.
2. Plan: compress intent
Planning turns research plus the product request or bug report into a sequence of concrete edits. A useful plan should include file names, relevant snippets, implementation order, and verification steps.
This is also where human review becomes high leverage. Reviewing a 30-line plan is easier than reviewing a 1,000-line diff. More importantly, it lets technical leads catch conceptual mistakes before the agent turns them into code.
Horthy frames this as “mental alignment.” Code review is not only about finding bugs. It is also how a team stays aligned on why the system is changing. In an AI-heavy workflow, plans and agent transcripts can become part of that alignment layer.
3. Implement: execute with a small context
Implementation should be the least surprising phase. If research found the right files and planning produced a concrete sequence, the agent does not need to be brilliant. It needs to follow the plan, make edits, run tests, and report deviations.
That is the point: move human attention to the highest-leverage parts of the pipeline. Humans should spend more time validating research and plans, and less time cleaning up giant diffs created from vague instructions.
Onboarding files help, but stale docs are dangerous
The talk also discusses repository onboarding context: files that tell the agent how a repo works. This can help, especially when split by directory or subsystem using progressive disclosure. A root-level guide can explain broad conventions, while deeper guides explain local details.
But there is a catch: documentation goes stale. The farther a piece of context is from executable code, the more likely it is to lie.
For that reason, on-demand compressed context is often safer than giant static documentation. Ask the agent to research the relevant code path now, from the current codebase, then compact only what matters for this task.
That does not mean teams should avoid docs. It means agent-facing docs should be treated like production infrastructure: scoped, maintained, and validated against reality.
Do not outsource the thinking
The most important warning in the talk is simple: AI cannot replace thinking. It amplifies the thinking you have done — or the lack of thinking you have done.
A bad line of code is a bug. A bad line in a plan can become a hundred bad lines of code. A bad research assumption can send the entire implementation in the wrong direction.
That changes where developers should apply scrutiny. In an agentic workflow, the highest-leverage review points are often:
- Is the research actually grounded in the code?
- Did the agent inspect the right files?
- Does the plan match the architecture we want?
- Are tests defined before the implementation runs wild?
- Is the task small enough for the current context?
If the answer is no, do not keep prompting forward. Stop, compact, correct, or restart.
A practical checklist for developer teams
If your team is trying to use coding agents on a real codebase, start with a few operating rules:
- Use one tool long enough to build judgment. Tool-hopping makes it harder to know whether failures are caused by the model, the prompt, the repo, or your workflow.
- Keep the main context small. Use subagents or separate sessions for broad investigation.
- Write research artifacts. Capture files, line numbers, constraints, and test entry points.
- Review plans before code. Plans are where human feedback has the most leverage.
- Include verification in the plan. “Run the tests” is too vague; name the commands and expected outcomes.
- Restart when the context is polluted. Do not drag a failing conversation across the finish line just because it already contains work.
- Avoid context-heavy integrations by default. MCPs and tools that dump large responses can push agents into failure modes faster than expected.
- Treat AI adoption as an engineering-management problem. If junior developers ship AI slop and senior developers clean it up, the workflow is broken — not the people.
The real shift: from prompting to workflow design
The future of coding agents is probably not one perfect prompt. It is better workflow design: research boundaries, compaction points, reviewable plans, scoped contexts, and verification loops.
That may sound less exciting than “the AI writes all the code,” but it is much closer to how real engineering teams can get value from these tools today.
The teams that win with AI coding will not be the ones that outsource all judgment to the model. They will be the ones that redesign their software delivery process so that models do what they are good at — searching, drafting, editing, executing repetitive steps — while humans stay focused on architecture, intent, correctness, and team alignment.
No vibes required.
Source
- Video: “No Vibes Allowed: Solving Hard Problems in Complex Codebases – Dex Horthy, HumanLayer” — AI Engineer, YouTube: https://www.youtube.com/watch?v=rmvDxxNubIg
- Transcript extracted from the YouTube captions for video ID
rmvDxxNubIgon May 11, 2026.